
こんにちは、nissyです。
「データ分析実務経験無し」で転職した化学メーカーで、研究開発DX推進に日々奮闘しております🔥
私の主な役割の一つに、開発チームに機械学習とマテリアルズインフォマティクスの重要性を説明し、彼らの理解と協力を得るということがあげられます。
しかし、機械学習の複雑さや重要性を伝えるのは簡単ではありません。なぜなら、私たちの日常の業務は分析やデータサイエンスの馴染みが薄いからです。
よくマテリアルズインフォマティクスに基づいた実験計画法を説明する際に、下記の様なイラストを用います。

この図は非常にシンプルで分かりにやすいのですが、シンプル過ぎるが故に本質が伝わりにくいのかなとも感じています。そこで本日は私なりのマテリアルズインフォマティクスの説明手順について書いていこうと思います。
製品開発は高次元空間で行われている
製品開発、特に化学製品の開発を考える時、それは高次元空間での複雑な作業となります。
塗料の製造を例に説明してみます🌈
塗料を作るには、「メイン樹脂、顔料、有機溶剤、消泡剤、防腐剤、その他添加剤」と様々な種類の原料が必要となり、これらをどのように配合するかが重要となります。
ここで仮に10種類の原料の配合量を調整して塗料を開発する場合を考えた時、これは実質的に10次元空間での最適化問題となります。さらに、原料についても様々な選択肢や組み合わせを考える必要があり、配合空間はさらに高次元化します。
このように、化学製品の開発は、非常に広い探索空間の中で最適解を見つけ出す作業になります。これは、広大な砂漠の中から指輪を見つけるような、非常に難しい探索と言えるでしょう。
この塗料開発をゼロベースで進めるとしたら、最適解に辿り着く確率は非常に低くなることは想像できると思います。
「何当たり前のこと言っているんだ」と思うかもしれませんが、これこそが機械学習とデータ駆動型アプローチの重要性を物語っています。
ドメイン知識により、配合空間を限定する
では、開発者たちはどのようにして高次元の問題に対処しているのでしょうか。その答えは、ドメイン知識(専門性や経験など)を用いて配合空間を限定することにあります。
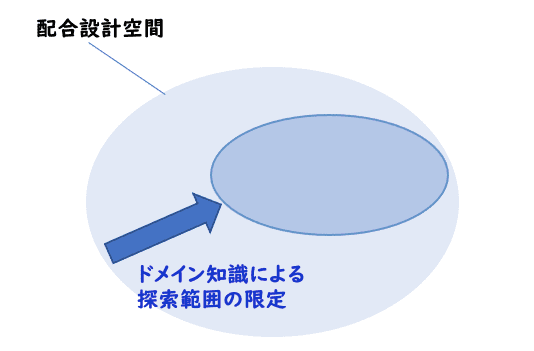
例えば、塗料における消泡剤の配合比を50%にすることは、常識的に考えてあり得ません。数パーセント程度が一般的です。
このような業界の常識や経験則が、開発者のドメイン知識を形成し、配合空間を効率的に限定し、最適解に近づく能力を高めています。
しかしながら、ドメイン知識を用いて限定された配合空間の中で、開発者には決められた納期までに開発を完成させなければならない時間的制約が発生します。つまり、実際に実験や試作できる範囲は、この広大な空間に比べると非常に非常に狭い範囲に限られるケースが多いでしょう。
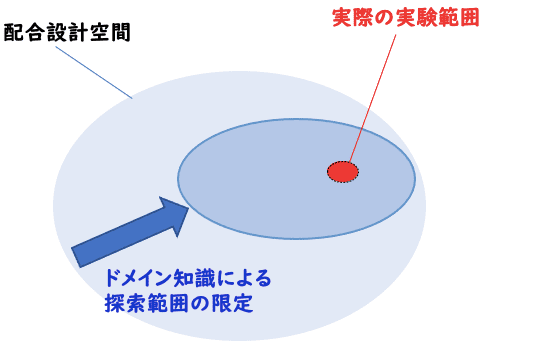
そして、このドメイン知識の深さが、開発者の能力を示し、社内評価や役割の差異を形成する重要な要素となっています。
しかし、ドメイン知識は、個人の経験や洞察に基づくため、その継承は難しい側面があります。特に、成功体験に基づくドメイン知識を持つ上級者は、自分の知識を過信し、自らの知識範囲外の可能性を見逃すリスクがあります。これは、部下教育においても大きな弊害になる可能性があると私は考えています。
成功体験に基づく知識の伝達は、部下の成長を促すのではなく、自身の再生産のループに陥りがちで、新しい視点やアイデアの探求を妨げると考えています。
この社内教育の問題については、後日別の記事で詳しく触れたいと思います。
過去の実験データで、探索範囲を拡大する
ここでは、マテリアルズインフォマティクスの重要性について掘り下げます。過去に行われた全ての実験データが利用可能だとすると、実験範囲は以下のように大幅に拡大されます。
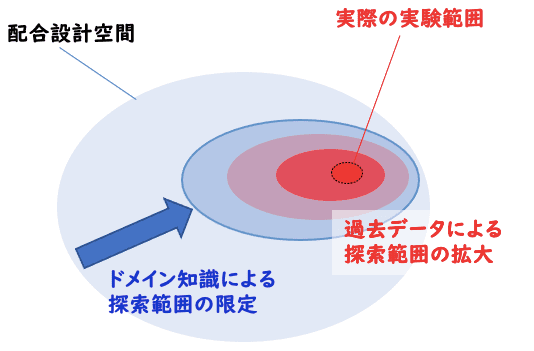
生身の人間では膨大なデータを処理し、最適解を探索することは難しいです。しかしながら、機械学習や深層学習といった技術を用いて膨大なデータを基に製品開発モデルを構築することで、探索範囲を効率的に広げることが可能になります。
この探索範囲を拡大する技術がマテリアルズインフォマティクスです!!!
新しい物性が製品の品質を決める規格となった場合、過去のデータは使えないからマテリアルズインフォマティクスは使えないわ
中々理解を得られずに、とりあえず適当な理由を並べてデータ共有システムの構築を後回しにすることもあるあるかもしれません。
しかし、実験データが十分にあれば、その活用方法は多様であり、様々な研究機関から新たなマテリアルズインフォマティクスの手法が提案されています。我々は、これらの研究成果にアクセスすることができる環境にあります。つまり、過去のデータが新しい問題解決に役立つ可能性は大いにあるのです。
もちろんデータを貯める際には、同一フォーマットで貯める必要があります。

これにより実験ノートに記録されているだけのデータは、再利用可能な知識へと生まれ変わります。
大勢でデータを共有することの利点
私がこれまでの実務経験を通じて感じていることの一つに、「個々人で機械学習を試みるのには限界がある」ということがあります。これは、私が支援した方々から得た教訓です。ここで、データをチーム内で共有する利点について考察します。
結論から言うと、「個人のデータのみで機械学習を行うと、限界を超える解を見つけるのが難しい」です。その主な理由は以下の通りです:
・データセットに開発者のバイアスがかかる: 個々の実験データは、その人の独自のノウハウや判断に基づいているため、必然的にバイアスがかかります。機械学習は、与えられた学習データに基づいて予測を行うため、このバイアスの影響を受けやすいです。そのため、既存のデータ範囲を超えて新しい解を見つけるのは難しいことがあります。
・既存の手法の限界: ベイズ最適化や遺伝的アルゴリズムなどの手法は、効率的に実験空間を拡大するのに役立ちますが、これらは基本的には既存のデータ範囲内での最適化に留まります。
これに対して、複数の実験者のデータを組み合わせることで、より広範なデータセットを作成することが可能です。この広範なデータセットを用いれば、個々のバイアスを超え、より多様なデータからの学習が可能となり、最適解の探索がより効率的になります。
私の仮説として、多数で共有されたデータ空間は、ドメイン知識の集合体と似た形状を持つのではないかと考えています。つまり、チーム全体の知見を反映したデータ空間は、より広い視野での問題解決を可能にします。
最後にゴールテープを切るのは、開発者のドメイン知識
機械学習やAIの技術は、データの分析や予測モデリングにおいて非常に強力なツールですが、これらはゴールテープを切るまでの道のりをより効率的にするものにすぎません。
最終的に最適解に到達するためには、開発者のドメイン知識が不可欠です。機械学習に入力するデータは特徴量の抽象化や物性値への置き換えなどが必要となり、それら学習データに基づいて出力された機械学習の予測範囲から、最適配合へと落とし込むためには開発者の深いドメイン知識が必要不可欠です。
ある人が「マテリアルズインフォマティクスはマリオカートで言うキノコ🍄の役割」と言っていましたが、非常に面白い例えだなと思いました。
AIの様なテクノロジーと親和性の高い人は、生身の人よりも何百倍も高い生産性を発揮すると思います。
まとめ
- 化学製品の開発は高次元空間で行われ、機械学習とマテリアルズインフォマティクスが、複雑な配合問題を解決するための重要なツールである。
- 個々の開発者のドメイン知識と経験は、膨大なデータを活用して効率的な実験計画を策定し、最適解を見つけ出すために不可欠。
- AIと機械学習は効率化の手段を提供するが、最終的な成功は開発者の深い理解と洞察によって決まる。


コメント