こんにちは、にっし〜です。
本日は「機械学習に読み込ませるための実験データのまとめ方」について紹介したいと思います。
少し前まではITとは程遠いと思っていた化学業界ですが、近年では大手化学メーカーで機械学習を活用した製品開発事例がニュースリリースされることも見かけ、マテリアルズインフォマティクスやプロセスインフォマティクス などの言葉の認知もどんどん広まってきている印象です。化学メーカーで働いている方の中にも、データサイエンティストやアナリストの仕事に興味はあるものの「今の仕事では実務経験を積むことができずに諦めている」「未経験歓迎の求人は見つけたが年齢制限に引っかかる」「転職すると今の労働条件より悪くなってしまい、挑戦に踏み切れない」という現実に直面し、なかなかキャリアチェンジに対して前向きな行動に踏み出せていない方も多いのではないかと思います。
早速データサイエンティストになるという挑戦を諦めようとしている方!!諦める前に是非「今の仕事に機械学習を取り入れる」という挑戦を行ってください。そして、その挑戦がデータサイエンティストへのキャリアチェンジを叶えるための立派な実務経験になります!
機械学習って大手化学メーカーの話でしょ。
自分の業務に機械学習を取り入れるなんて無理だよ。
そんなことはありません。
実験データを機会学習用の型で整理すれば簡単に使えます。
- 化学メーカーで実験・分析データを扱っている方
- 自分の業務に機械学習を取り入れてみたいと思っている方
- データサイエンティスト転職に興味がある化学メーカー技術職の方
- 化学系の大学院を修了
- 新卒で大手化学メーカーに入社、9年間で工場勤務(品質管理)→研究棟勤務(製品開発)→本社勤務(マーケティング)を経験
- 30代でデータサイエンス系の大学院を修了後、転職により化学メーカーのデータサイエンティスト職に従事
機械学習が読み込めるデータセットの型とは
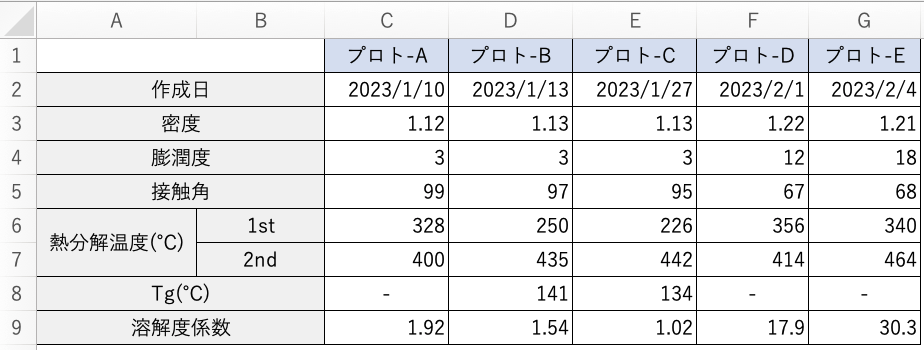
化学メーカーで製品開発をされている方で、以下のような形式でデータをまとめていませんか?
このように横にデータを貯めている形式のデータセットは人にとっては理解しやすいですが、機械学習を活用する側にとっては全く嬉しいデータセットではありません。「データ整理からしなきゃあかんやんけ!」ってなります。
機械学習を活用するならデータセットは以下のような形式にしなければなりません。この形式で下方向にデータを貯めていきます。
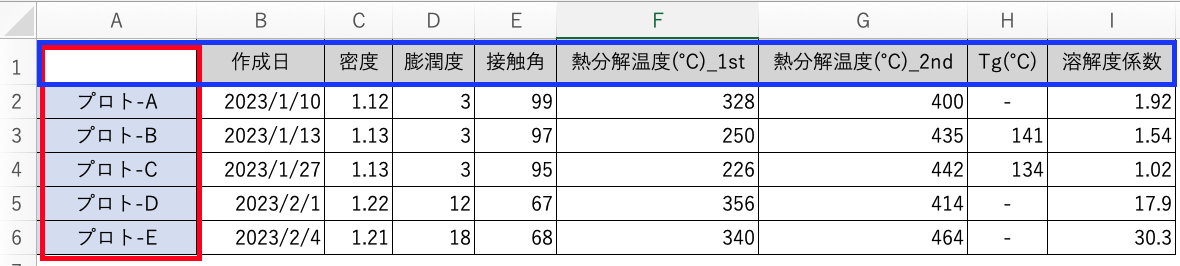
合わせて用語について説明します。
まず赤枠で括られている部分をまとめてサンプルと呼びます。
次に青枠で括られている部分ををまとめて特徴量、変数(説明変数、目的変数)と呼びます。またデータセットの列つまり項目が追加されることをを「次元が増える」と言います。
次元という概念は化学ではあまり出てこないので覚えておきましょう
以上を踏まえて、著者は実験データをリレーショナルデータベースぽくまとめることをお勧めします。
リレーショナルデータベースとは
リレーショナルデータベースとはデータを表形式で管理するデータベースであり複数のデータセットをくっつけることができるよう各々のデータセットを設計します。
リレーショナルデータベース形式でまとめるメリット3選+おまけ
機械学習でのデータ解析ができる。
機械学習を活用してあなたの実験データを解析することができます。基本的にはPythonというプログラミング言語を使ってのデータ分析を想定しています。
データの結合、抽出が容易にできる。
Pythonを使って複数のデータセットを結合させたり、欲しい条件を指定すれば(例:Tgが100℃以上の高分子)その条件にマッチしたデータのみを簡単に取り出すことができます。
かっこいいグラフが簡単に作れる。
Pythonのライブラリーを使えば様々なグラフを作成できるのはもちろんのこと、エクセルでは出せなかったかっこ良さを出すことができます。
私は「Python グラフ かっこいい」で画像検索してグラフを探してるよ
(おまけ)グループでの実験データ管理する際のルールが明確。
リレーショナルデータベースのルールをグループ内で徹底させれば、データの蓄積が用意になります。ただルールを徹底するのが難しいんですよね。だって人間だもの(笑)
リレーショナルデータベース形式でデータをまとめてみよう。
項目を設定しよう。
データでまとめる上での項目を書き出してみましょう。設定する項目は化学業界の中でも扱っている分野・製品によって大きく変わるので、状況に応じて難しさが出てくると思います。
行が増えるのはOK、列が増えるのはNG。
データセットの項目を設定し、データをため始めてから列を増やすのはあまり良くありません。データ貯め始めてからは列が増えないように項目設計する必要があります。
最終的には結合することを前提として項目設計する
複数のデータテーブルをPythonで結合させたり、抽出したりして扱うことを前提に項目設計する必要があります。ですのでデータセットの中に「実験コード」「材料コード」「ロット」「測定日」「担当者」といったキーとなるデータを入れる必要があります。また、結合させて使うことが前提なので、無理に1枚のシートに全てのデータを入れようとしなくて大丈夫です。
セルを結合をしてはいけない。
セルを結合して項目を見やすくしたい気持ちはわかりますが、機械に読んでもらうためにセルの結合はしないようにしましょう。
リレーショナルデータベース形式でまとめる際の疑問点(経験談)
著者は所属部門の実験データを回収してデータベースの形式でまとめるという仕事(雑務)をしたことがあり、その時に直面した困難とそれを乗り越えた方法についてまとめています。
スペクトルデータはどうすれば良いか?
1つのスペクトルデータに対して1ファイルで管理した方が扱いやすいと思います。注意事項としてファイル名は統一されたルールをもとに付けられていた方がPythonを使ってデータを読み込む時にコードを書くのが楽になります。
測定項目で複数の条件があるデータはどのようにまとめれば良いか?
実験条件が製品によって決まっている場合は以下のように項目を固定させて良いです。
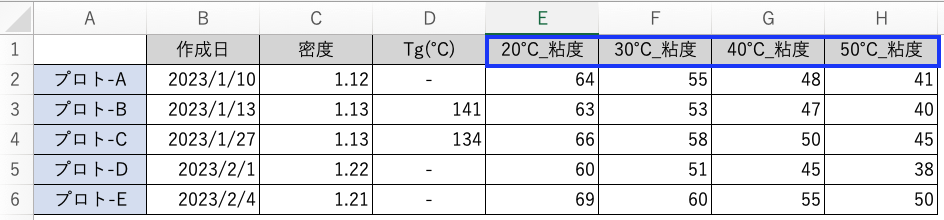
ただしケースバイケースで実験条件が変わる場合は、その実験専用のファイルを作成し実験データを管理しましょう。
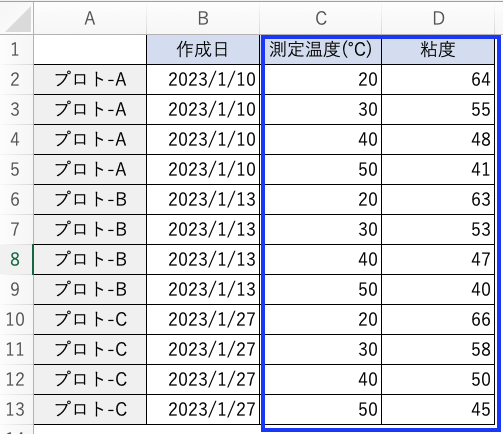
実験結果が感覚値がの場合どうすれば良いか?
できるだけ定量化できる指標を作れるかを検討します。定量化が難しい場合、例えば5択から選ぶようにするなど選択肢の数を決めることができればダミー変数を用いて機械学習で解析できるようになります。
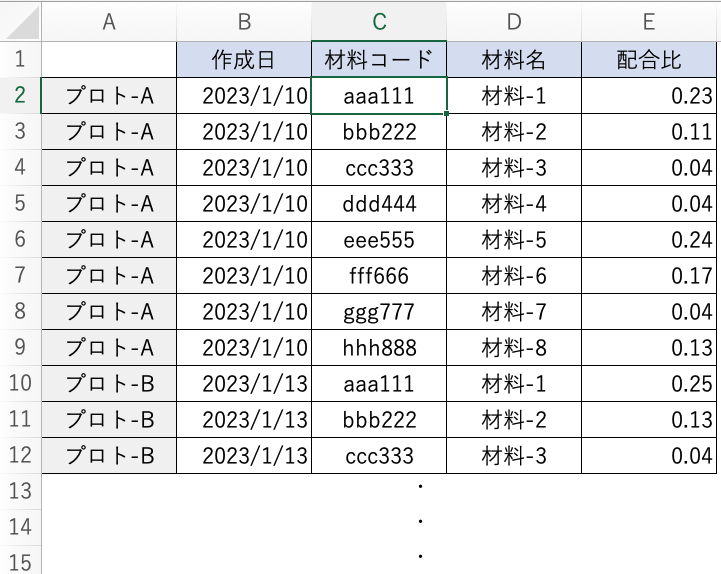
実験配合のデータセットはどのように作れば良いか?
以下のように列方向にデータセットを作成します。材料の物性データがある場合、配合と材料物性データを結合することができます。
まとめ
- 人間が見やすいデータセットと機械が読み込みやすいデータセットは異なる。
- 今の実験しているデータをリレーショナルデータベースの型で管理しようとしたら何枚のシートでどんな項目を設定しすれば管理できるかを日々考える。
- 実験データもリレーショナルデータベース形式に管理をすれば機械学習の恩恵を受けることができる。
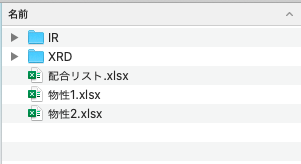
あくまで一例ですが、フォルダ内はこんな感じです。このフォルダがテーマ毎にいくつもあるイメージです。
データサイエンティスト転職のための実務経験につなげましょう!


コメント