
こんにちは、nissyです。
本日は「機械学習は”経験と勘”のプロセスから脱却できる手法」というテーマで記事を書かせていただきす。
機械学習やAIに対する知識が不足している事によることで、”胡散臭く思ったり“または”過度に崇高なものと捉え“距離を作ってしまっているのかもしれません。
しかしながら、機械学習のアルゴリズムは全て数学的に説明することができるので決して胡散臭いものではありません。
機械学習はあなたが行なってきた実験や実務に対して得られたデータを分析して考察するためのツールとして有効活用できます。
マテリアルズインフォマティクス〜機械学習を活用とした実験計画法〜
マテリアルズインフォマティクスとは統計分析・機械学習などの情報科学の技術(インフォマティクス )を用いて材料開発を効率化する技術のことです。
例えば、製品設計のための検討レシピの条件を説明変数(X)とし、レシピ通り作った製品の物性を目的変数(Y)に取り機械学習モデルY=f(X)を構築します。
構築した機械学習モデルをうまく活用することで、できるだけ少ない実験回数で目標の物性を達成することができます。すなわち、機械学習を活用した実験計画法です。
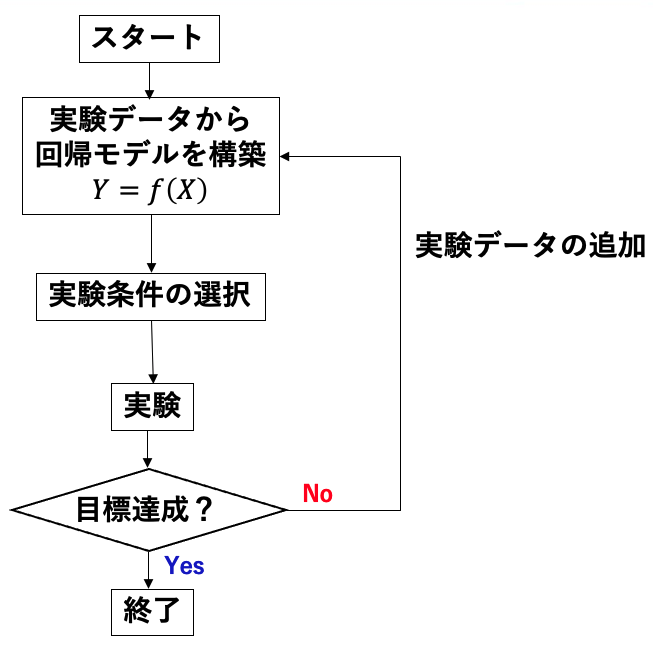
より分かりやすくを機械学習を活用した時の実験フローの違いを捉えていただきたく、「人が考える実験水準」と「機械学習を使った場合の実験水準」を比較していきたいと思います。
人はどうやって実験水準を決定する?
私は化学メーカーでデータサイエンティストとして働いており、職業柄様々な開発者の実験データを見る機会があります。その経験から言えることは、人は「Pointとして着目している特徴量以外の特徴量は固定しがち」ということです。
(データテーブルを用いてパラメータ最適化のイラストを添付)
上記の何が問題かと言うと、“1つの実験から得られる情報量が少ない“ということです。このままではよく分からないと思うので、テーブルデータを使ってペアプロット図を作成して実験条件を可視化してみましょう。
(ペアプロット図を添付)
ペアプロット図を見てみると、プロットが縦横に並んでいる傾向が確認できると思います。実験条件を固定している特徴量が多いが故に、自然とこの様なペアプロット図が作成されるような実験水準を組んでしまいます。
この様なプロットが縦横に並んでいる傾向は、その特徴量に対して分散(バラつき)が小さいことを意味しています。分散が小さいということは情報科学の分野では情報量が少ないこととイコールなので、情報量の少ないデータセットからは精度の高い機械学習モデルは構築できません。
精度の高い機械学習モデルを構築するためのデータセット
次に機械学習を使った場合の実験水準について見ていきましょう。機械学習を活用するということは、精度の高い機械学習モデルを構築するためのデータセットを用意してあげる必要があります。それは情報量の多いデータセットです。
それでは情報量の多いデータセットと情報量の少ないデータセットを比較して見ましょう
(ペアプロット図を添付 D最適と人のデータセットを横並び)
横並びにして見てみるとプロットのバラつき方が全然違うのがわかると思います。左のデータセットの方がプロットが網羅的にばらついているので探索範囲が広いことが直感的にもわかると思います。
情報量の多いデータセットの作り方
情報量の多いデータセットを作成するために、実験計画法ではD最適基準という指標に基づいて実験条件を選択します。具体的には以下の様な特徴を持つ実験水準が選択されます。

精度の高いモデルを構築できる数学的説明 〜重回帰分析をスムーズにスタートできる〜
D最適基準に基づき実験条件を設定すると情報量の多いデータセットが作成できるので、比較的少ないサンプル数でも精度の高い機械学習モデルを構築することができます。別の記事でも紹介した様にサンプル数に応じて機械学習モデルを使い分ける必要があります。
(サンプル数と機械学習モデルの図を添付)
サンプル数が少ない場合は重回帰分析の様なモデルを使うのが良いです。重回帰分析のパラメータは最小二乗法を用いることで解析的に導くことができます。
「解析的に」とは「紙の上にペンで書いて」導出することができるということです。
・重回帰分析の最小二乗法によるパラメータ算出例を記載(X=データセット、Y=データセットの図表も忘れずに)
・D最適機銃の方針と重回帰分析の最小二乗法と繋がりを説明
機械学習が人に与えるメリット
ここからは機械学習が開発者に与るメリットについて紹介します。実験が効率化できること以外にも、開発者の成長につながるメリットがたくさんあります。ここでは私が実務を通じて感じたメリットについて紹介したいと思います。
“材料”ではなく材料の”物性・特性”を考えるようになる。
別の記事でも紹介した様に、機械学習にデータを読み込ませるためには定量化されたデータセットを作成しなければなりません。このデータセットは「経験と勘」の製品設計で留まっている人には作成することはできません。
具体的にどういう意味か説明します。
例えば、長年にわたり製品開発を行ってきたAさんは頻繁に材料Bを使った配合設計を行っているとします。そうするとAさんは経験的に材料Bについての理解が進みます。
物性Cを向上させたかったら、材料Bを添加すれば良いぜ!!
上記の様な情報の積み重ねで製品開発を進めることが俗に言う「経験と勘」に基づいた配合設計です。この様な情報を積み重ねることでで製品を開発するはもちろん可能です。しかしながら、この様な情報のままでは機械学習に読み込ませることはできません。情報の定量化が不十分なためです。
機械学習に読み込ませるデータセットを作成するためには
粘度〇〇、吸光度□□、Tg△△の材料Bを5%増量したら物性Cは○%向上する
といった感じに詳細に噛み砕いて定量化しなければなりません。この情報の定量化については様々な意見があると思います。「使用している材料の種類が膨大すぎて整理するのは無理」「すべての物性を測定するのも無理」「材料情報を完璧に把握することなんて不可能」この様にデータセットを作成する段階で高い壁に直面し、機械学習を活用することを諦めてしまう人が多数派でしょう。
この様な意見に対する私の考えは、「出来ないものを考える必要はない。出来そうなものをしっかりと揃えることから始めましょう。」です。
企業が抱えるデータ活用の壁を突破するための研究はたくさんされています。データの代替や欠損値処理の方法についても研究報告はされていますし、論文や特許などから情報を抽出しデータベース作成するといった取り組みも活発に行われています。
皆さんが直面する壁はすでに誰かが直面していて、それを突破する方法についても考えられています。ですので機械学習を活用することを諦めるのではなく、出来そうなことに目を向けていただきたいと思っています。
製品開発・実験に関する議論が活発になる
データを学習した機械学習は、新しいデータセットに対して統計的に最適な解を出力してくれます。仮に“絶対にあり得ない実験条件”を入力してもの計算シミュレーションを実施することができます。この特性を利用すれば、実験を行う前の段階で“目標達成確率の高い実験条件を探索”することができます。
実験条件探索の流れを説明しますね
(俺のパワポ を参考)
乱数の範囲を広げればその実験条件が現実的か非現実的かはひとまず置いといて、達成確率の高い実験条件を出力することができる。
大事なのは不可能な実験水順を見ることではなく、出力された実験条件の中で”実施可能な条件”から“目標達成確率が高い”実験水準に着目することです。機械学習が出力した結果も一つの意見として、次にどの様な実験を行うかグループ内でディスカッションを活発にできる様になります。
まとめ 〜「vs AI」ではなく「with AI」〜
今回は「機械学習は「経験と勘」のプロセスから脱却できる手法」と言うテーマについて紹介させていただきました。これまで「経験と勘」に頼っていた製品開発により得られたデータでは機械学習に読み込ませることができません。しっかりと定量化されたデータセットが必要になります。そのためには開発者自身がデータの持つ情報を理解し定量化させなければなりません。
近年では「経験と勘」に頼った製品開発・ノウハウ整理などの属人化した状況から脱却したいと考えている企業もたくさんいると思います。その状況から脱却する手法として機械学習を用いるのではなく、機械学習を活用した製品開発をする環境を構築することができればその状況から脱却しているでしょう。


コメント