
こんにちはnissyです
機械学習を用いたいと思うときは、何か解決したい課題があるときです。
ですが、機械学習は全て自動で課題の解決方法・最適解を出力してくれる魔法のツールではありません。当然課題解決のために人の手間もかかります。
機械学習モデルを構築する手順として3つステップに分けることができます。
- 人:(1st). 探索範囲を決める (2nd). 評価指標を立てる
- 機械学習:(3rd). 最適解を探索する
人と機械の役割、それぞれについて説明していきます。
- 化学系の大学院を修了
- 新卒で大手化学メーカーに入社、9年間で工場勤務→研究棟勤務→本社勤務を経験(ジェネラリストコースのキャリアを歩む)
- 30代でデータサイエンス系の大学院を修了(リスキリング)
- 転職により、化学メーカーのデータサイエンティスト職として従事
探索範囲を決める(人)
機械学習モデル構築における探索範囲は”学習データ”に依存します。
研究開発の場合で言うと、ある開発者の考えを確立している「経験・知識・勘」するに至った実験データがそれに該当します。
良質なデータセットというのは探索範囲が広く、情報量が多いデータセットです。
開発者も数多くの失敗を経験して今の考えを確率しています。
その開発者の経験を含んだ良質なデータセットを用いて構築した機械学習モデルは、先人たちの「経験・知識・勘」を取り込んだ機械学習モデルと言え、直感的に「結果の予測」や「再現実験の精度」が高くなりそうです。
実際、探索範囲の広いデータセットは機械学習モデルの精度にも良い影響を与えます。
探索範囲の広さがモデル精度に良い影響を与えることを確認するために、簡易的な実験をしてみたいと思います。
まず真のモデルとして \(y=0.5x+1\) を用意します。
真のモデルからノイズを乗せて発生させたデータに対して、最小二乗法を用いた単回帰分析でフィッティングを行います。ノイズは平均0、標準偏差0.5の正規分布に従うとします。
xの範囲を[-5,5]と[-1,1]でフィッティング精度を比較します。
結果を以下のグラフに示します。発生サンプル数はそれぞれ10、20、50です。
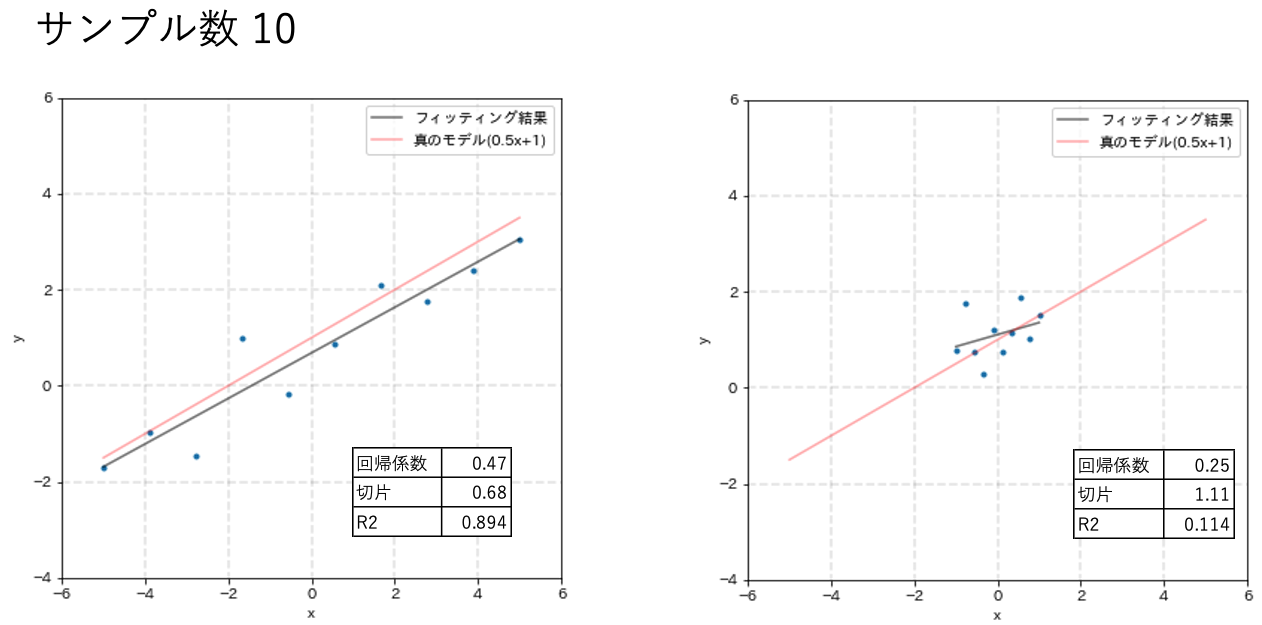
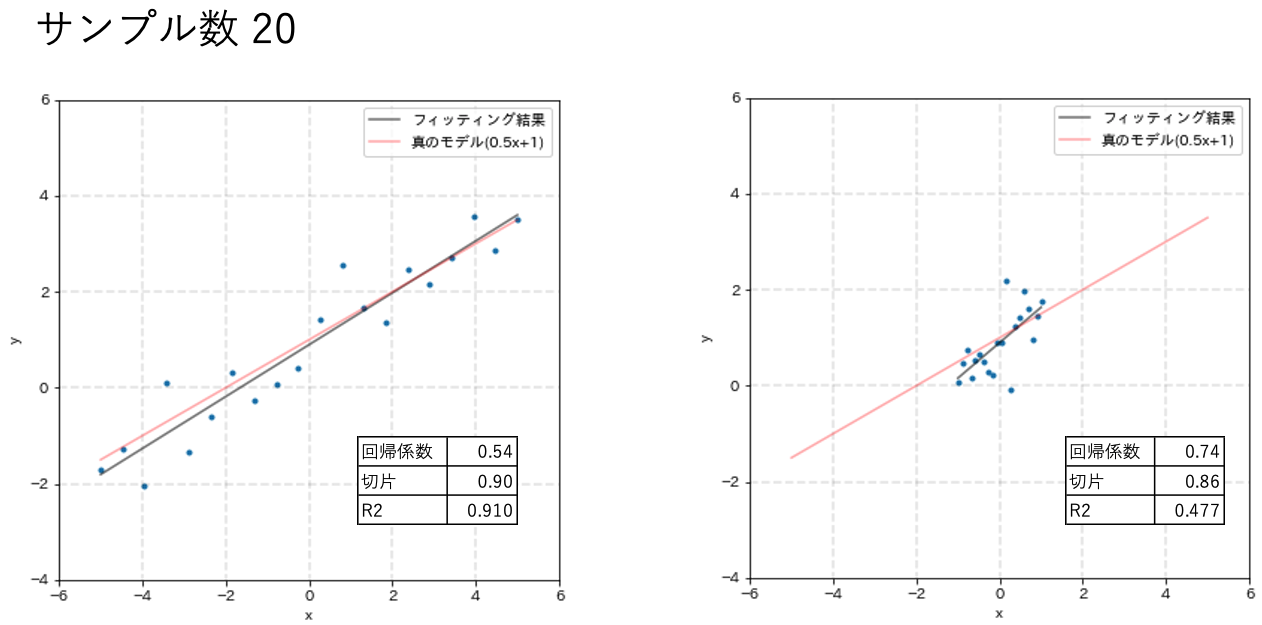
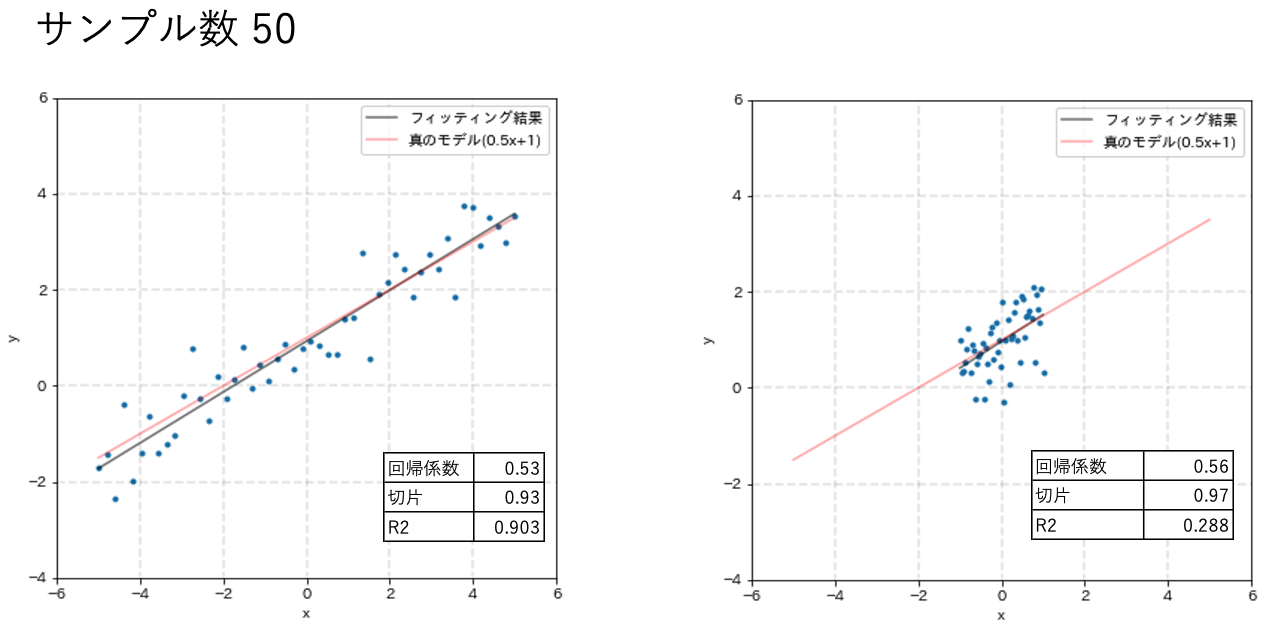
少ないサンプル数(N = 10、20)の時に着目してください。探索範囲が広い方が真のモデルに近い回帰直線を直線を引けている事がわかると思います。
さらに、N=50に着目すると探索範囲が狭い方も真のモデルを表現できていますが探索範囲が広い方と比べて決定係数がかなり小さい事がわかります。
探索範囲を広げない局所的な実験を継続してしまうと正しく真のモデルを表現できていても評価指標の値が悪く、結果を疑ってミスリードに繋がってしまう可能性が高まってしまいます。
この様に、探索範囲の広いデータセットは少ないサンプルでもモデル精度に良い影響を与えることが直感的にも理解できたと思います。
評価指標を立てる(人)
機械学習は目的関数を小さくする様にパラメータ空間から最適解(パラメータ)を探索します。
機械学習モデルを構築する場合、何を持って最適解とするかを決めるための構築したモデルを評価するため指標を設定する必要があります。
評価指標というのは目的に応じて使い分ける必要があります。例えば「未知データに対する予測精度を上げたい」のか、「真の要因を特定したい」のかで立てる評価指標が変わってきます。
また解く問題も分類なのか回帰なのかで変わってきます。
回帰の場合、決定係数、RMSE、分類の場合、適合率や再現率、AUCを用いたりします。
解くべき問題に対して適切な評価指標を立ててあげるのは人の役割です。
最適解を探索する(機械)
機械学習モデルは人が容易した選択肢の中で最適解を探索します。
例えば課題の最適解を解明したいと思いランダムフォレストを機械学習モデルを構築した時に
「サポートベクターマシーンの方が良いモデルができそうです」みたいな解は返ってきません。
ランダムフォレストとサポートベクターマシーンの両方でモデル構築を行い、評価指標に基づきどちらが優れているか判断します。
当然ながらデータセットが変われば、最適なモデルも変わってきます。
結果は探索範囲と評価指標が決まった後に決まるものです。
下図の様な損失関数の中から大域的局所解を探索しているイメージを持っている方は意外と機械学習がやってくれることって少ないんだなと感じた方もいるかと思います。
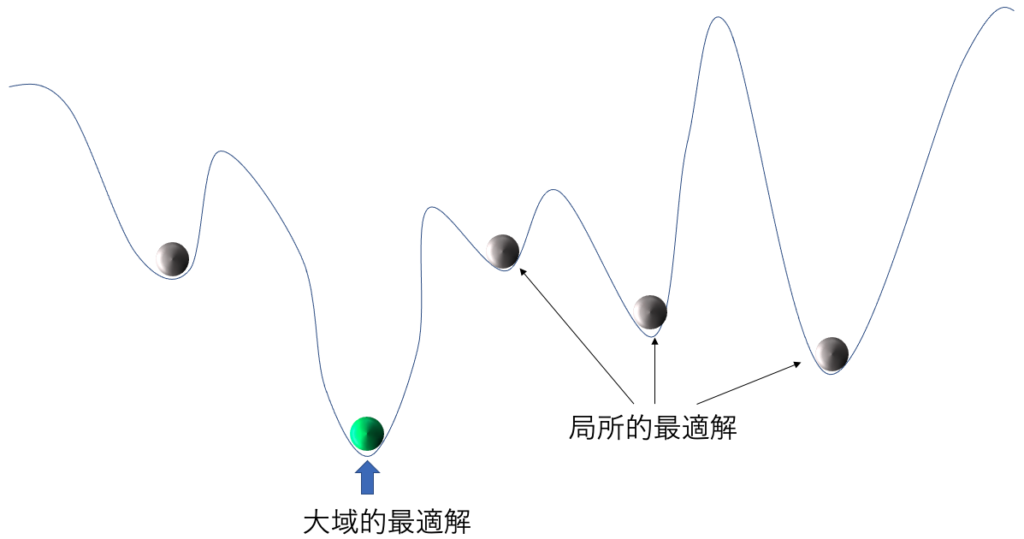
ですが、機械学習を侮るなかれです。高次元かつ複雑なパラメータ空間から最適なパラメータを探索しています。人がやるとしたら想像を絶する骨の折れる作業です。

引用元:Hao Li .et.al , Visualizing the Loss Landscape of Neural Nets, (NeulPS 2018)
実務でも使える考え方
これまでの機械学習モデル構築の流れを整理して気づいたことをまとめます。
- 探索範囲を機械学習モデル構築において探索範囲、評価指標が決まらないと最適解は定まらない。
- 探索範囲、評価指標が変わると最適解は変わる
よく仕事においても、あるプロジェクトの進捗報告の会議の場で議論が空中戦になっている状況によく出くわします。
そんな時は大体「探索範囲と評価指標を定義せずに、結果において議論を行っている」ケースが多いと感じています。
探索範囲、評価指標が不透明な中で「それは意味ない」「やってみないとわからない」という議論は不毛です。
私自身は何かを決めるための議論を行う時は探索範囲、評価指標の部分にフォーカスするように心がけています。
そうする事で「探索範囲を広げる・変える」、「評価指標を変える」といった類のわかりやすいアクションプランに繋がると考えているためです。
まとめ
機械学習は全て自動で最適解を出してくれる魔法のツールではありません。精度の高い機械学習モデルを構築するためには人による役割が大きいです。
人が定めた探索範囲、評価指標に基づいて機械学習は最適解を導いてくれます。
このフローは実務においても応用可能で、会議や議論の場で空中戦になって具体的な次のアクションが決まらない経験をしたことがあるという方は、探索範囲と評価指標を議論のポイントにおいて話し合いを進めてみてください。

コメント